Summary of implementing a toy MapReduce
What is MapReduce
Introduction
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key /value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
Execution
- The MapReduce library in the user program first splits the input files into M pieces of typically 16 megabytes to 64 megabytes (MB) per piece (con- trollable by the user via an optional parameter). It then starts up many copies of the program on a clus- ter of machines.
- One of the copies of the program is special – the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task.
- A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The interme- diate key/value pairs produced by the Map function are buffered in memory.
- Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
- When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all in- termediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together. The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fit in memory, an external sort is used.
- The reduce worker iterates over the sorted interme- diate data and for each unique intermediate key en- countered, it passes the key and the corresponding set of intermediate values to the user’s Reduce func- tion. The output of the Reduce function is appended to a final output file for this reduce partition.
- When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, the MapReduce call in the user pro- gram returns back to the user code.
- After successful completion, the output of the mapre- duce execution is available in the R output files (one per reduce task, with file names as specified by the user). Typically, users do not need to combine these R output files into one file – they often pass these files as input to another MapReduce call, or use them from another dis- tributed application that is able to deal with input that is partitioned into multiple files.
Overview of this toy MapReduce
Following the lab instructions, what I implemented is a MapReduce whose map is a function that takes several articles as input and split the words inside into key/value pairs, in which the key is the word itself and the value is 1; and the reduce function adds the values of each key (since a word may repeats) and finally writes them into final files (corresponding to each article) in the format of key count.
There are two phases , one is the Map phase, in which it writes the results of the map function into a intermediate files. After all map tasks finish, the program proceeds to the Reduce phase, in which the program takes the intermediate files as input and writes the final results to the output files after being processed by the reduce function.
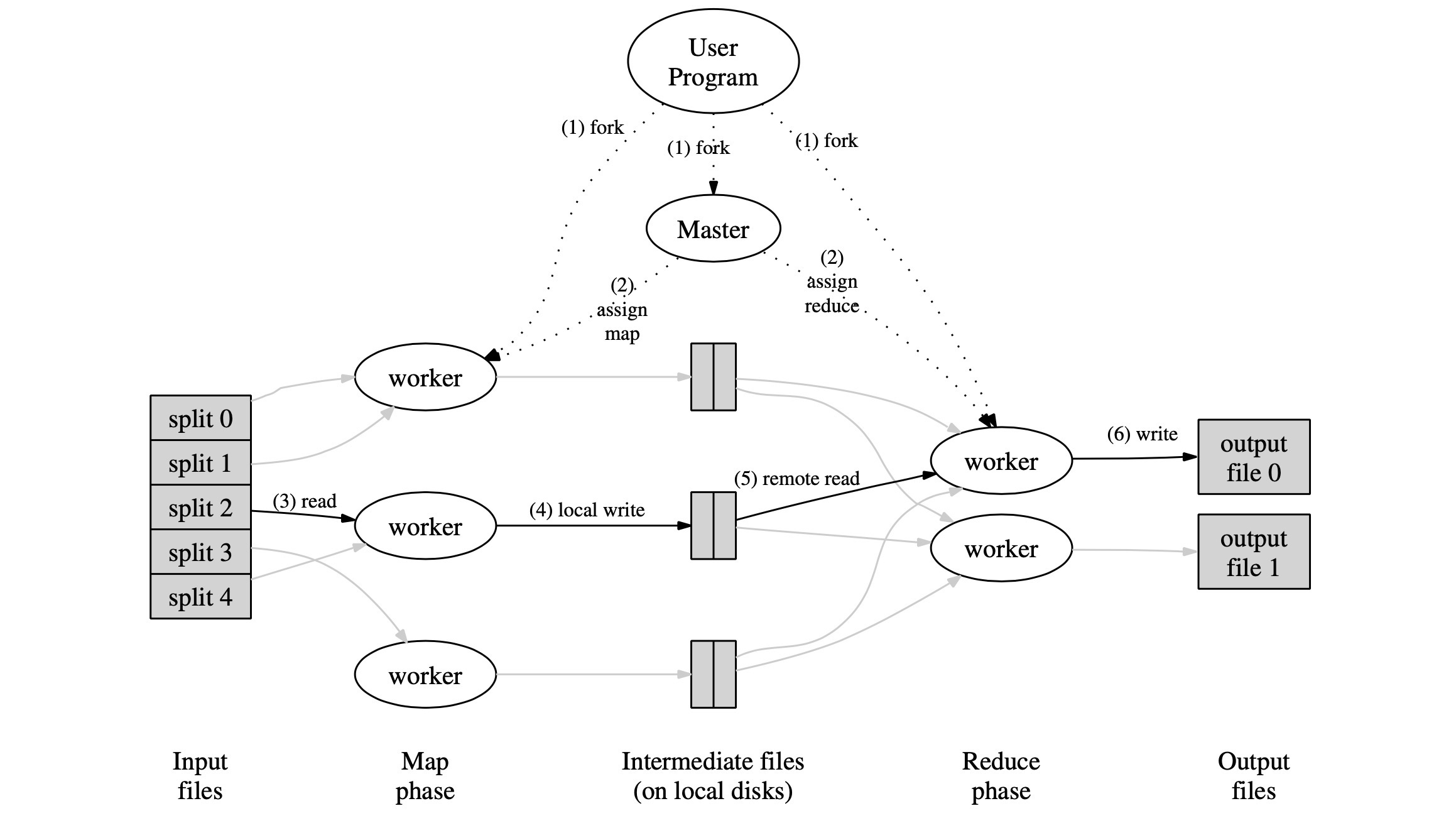
The transition from the Map to Reduce phase is controled by Master node, under which there are multiple worker nodes (set up by users) waiting for jobs. Moreover, the master node is responsible for the task scheduling. Once the Map phase finishes (or all the map tasks finish), the master will then generate the reduce tasks and again assign them to workers.
The interaction between Master and Worker are handled by RPC (remote procedure call). Once the worker finish its task, it will ‘call’ the Master to assign another task to it if the master have unifinished tasks stacked in the list.
Challenges
- The master, as an RPC server, will be concurrent.
- The system should be fault-tolerant, which means one or several workers crashing will not affect the master and the other workers.
- The master cannot reliably distinguish between crashed workers and workers that are alive but have stalled for some reasons. Besides, workers that are executing but too slowly to be useful.
- Overlappingly writting to the same file may occur to the workers that are executing too slowly and the worker that is ‘sophisticated’ and get the same task.
Address Challenges
Using Mutex lock in master server (ps: the granularity of the lock is out of the scope of this blog).
There are several operations needing to be guranteed sequentially.
- Task distribution should guarantee that a task would not be assigned twice except the case of dealing with slow or crashed workers.
- Process the results returned from workers. To be specific, the master need to sequentially record the intermediate file paths after the map phase.
To distinguish crashed workers, timestamps should be included in each tasks’ meta data when created. Moreover, for building a fault-tolerant system, a routine that monitors each unfinished task should be implemented. The job of this daemon routine is to check if overtime happens in tasks. Backup tasks will be scheduled after a relatively period of time (e.g., 10s).
To ensure that no partially written files would be observed, the MapReduce paper introduces a trick of using a temporary file and atomically rename it once it is completely written.
// in Golang
// to create a temporary file
tempF, err := os.CreateTemp(dir, "mr-tmp-*")
// to atomically rename the file
err = os.Rename(tempF.Name(), fileName)
Data structures
RPC - Task structure
-
Input file
-
Output file
-
Task number (To ensure the entirety of a file)
-
Number of Reduce jobs
-
Phase (Map | Reduce | Wait | Exit) (ps: Waiting phase is to control worker when there is no task in the task queue.)
Master
- MasterTask
- Start time
- Task state (Idle | InProgress | Completed)
- TaskReference (*Task)
- Master
- List of input files
- All intermediate files
- Number of Reduce jobs
- Phase: (Map | Reduce | Wait | Exit)
- TaskList (channel *Task)
- Map of task metadata (key (task number) / value (*MasterTask))
Reference
Jeffrey Dean and Sanjay Ghemawat. 2008. MapReduce: simplified data processing on large clusters. Commun. ACM 51, 1 (January 2008), 107–113. https://doi.org/10.1145/1327452.1327492